1. 元字符和语法
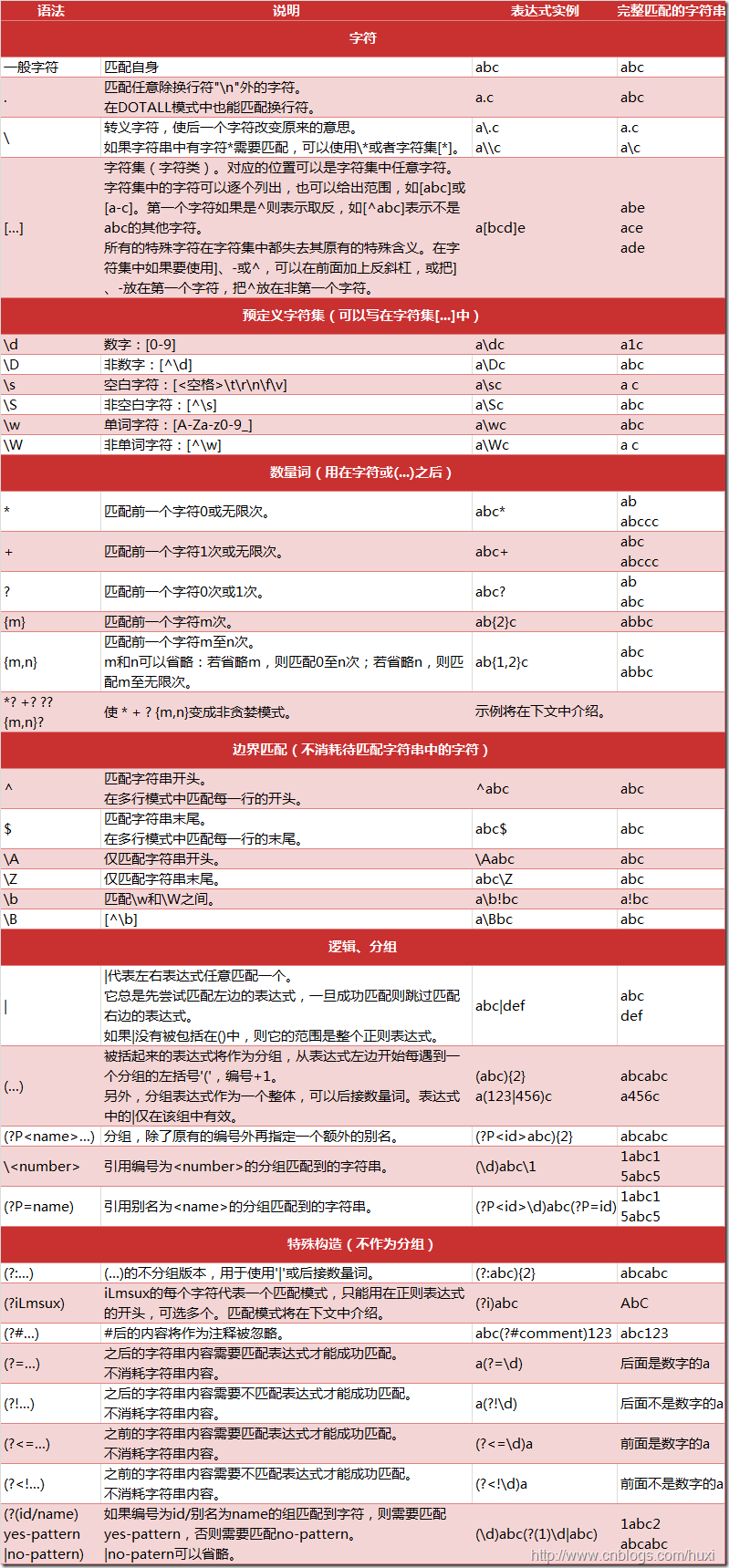
2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),
总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式”ab“如果用于查找
“abbbc”,将找到”abbb”。而如果使用非贪婪的数量词”ab?”,将找到”a”。
3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用”"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符
“",那么使用编程语言表示的正则表达式里将需要4个反斜杠”\\“:前两个和后两个分别用于在编程语言里转义成
反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这
个例子中的正则表达式可以使用r”\“表示。同样,匹配一个数字的”\d”可以写成r”\d”。有了原生字符串,你再也
不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
4. 匹配模式
flag是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile(‘pattern’, re.I | re.M)与re.compile(‘(?im)pattern’)是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变’^’和’$’的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变’.’的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。
5. re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
re.match(pattern, string, flags=0)
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs"
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
6. search
这个方法用于查找字符串中可以匹配成功的子串
pattern_str = r'.*' + key + r'\s*[,)]'
match_obj = re.search(pattern_str, content)
if match_obj:
print(match_obj.group())
7. finditer
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
能得到所有的能匹配到的,并且分组也正常
pattern_str = r'\s*\w+_(MSG|MESSAGE)\([^,;]*?printMsg\s*\(\s*' + key + r'\s*(,[^;]*)*\);'
match_obj = re.finditer(pattern_str, CONTENT, re.M | re.S)
not_matched = True
for m in match_obj:
not_matched = False
match_str = m.group().strip()
match_arg = m.group(2)
print('matched str in [%s]: \n%s' % (file_name, match_str))
print('args of matched str in [%s]: \n%s' % (file_name, match_arg))
if not_matched:
print("No match key: %s in the file [%s]" % (key, file_name))